Method
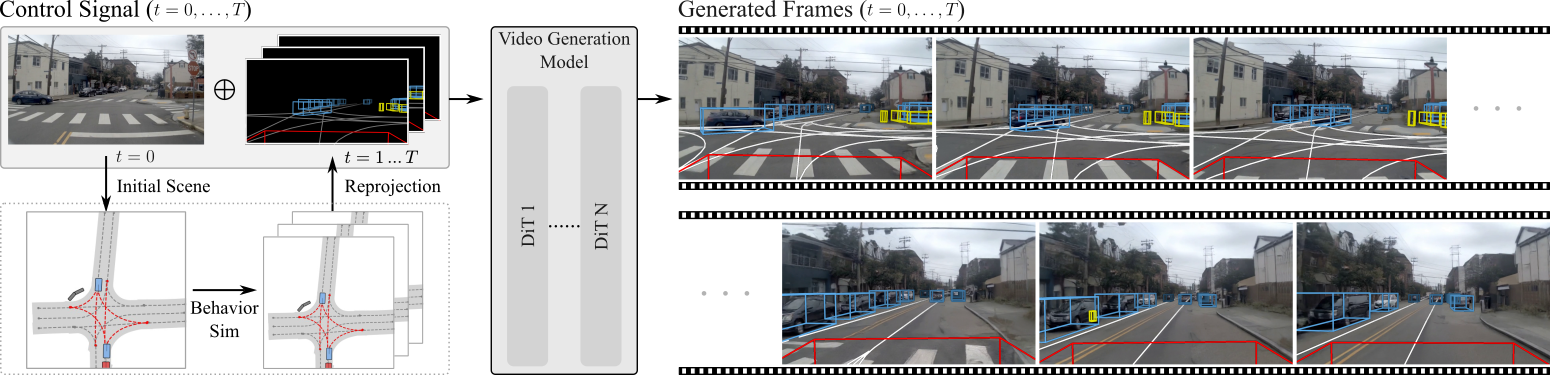
ScenarioControl models each scene as a graph of objects and lane centerlines in a bird's-eye view, with per-object elevation for image-domain reprojection. A controllable latent diffusion model (conditioned on text prompts or agent-view images) produces this vectorized representation in a single forward pass. A gated cross-global control mechanism fuses conditioning signals with sparse scene tokens, while a count-injection head controls lane and agent cardinality - enabling fine-grained edits to road layout and traffic composition.
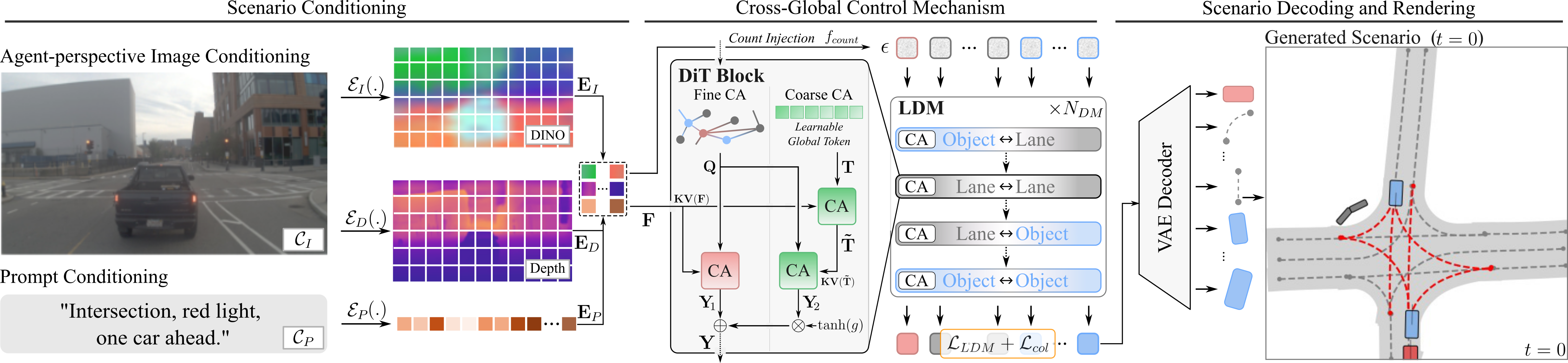
The vectorized scene representation feeds existing BEV-space behavior simulation, whose output is projected into wireframe control signals for video generation. We train two video-model variants: an image-conditioned model that derives appearance from the first frame, and a prompt-conditioned model whose appearance follows a text description.